
Dependency-Track is a powerful tool for managing software components and their associated vulnerabilities. As your project portfolio expands, gaining a clear, aggregated overview of your risk posture becomes paramount. This is where a feature of Dependency-Track’s project management capabilities, Project Collections, can be a big help to you. By effectively utilizing Project Collections, often in conjunction with parent-child hierarchies and tags, you can significantly streamline your workflow, achieve superior visibility into component risk, and make more informed security decisions.
This blog will focus on the Project Collections feature, exploring how it helps you aggregate and analyse data from multiple projects. We’ll also touch upon how parent-child structures and tagging complement and enhance the power of collections.
Understanding Project Parent-Child Hierarchy: A Foundation for Collections
What is it?
Before diving deep into Project Collections, it’s helpful to understand the Project Parent-Child Hierarchy. This feature allows you to structure your projects in a way that mirrors real-world application architectures. You can define a “parent” project that has multiple “child” or sub-projects. Think of a main application (parent) with several distinct library modules or microservices (children) that are tightly coupled.
Key characteristics:
- Child projects are distinct entities, but are directly linked to a single-parent project.
- Each child project maintains its own Software Bill of Materials (SBOM), components, and vulnerabilities.
- This hierarchical data (vulnerabilities, metrics) from child projects is what Project Collections primarily aggregate and display at the parent level.
Why is it relevant to Collections?
- Accurate Representation for Aggregation: It accurately reflects complex application structures, providing a logical structure to roll-up data in Project Collections.
- Granular Data Source: Enables tracking at the library modules or microservices level, with Project Collections then providing the aggregated risk view from these granular sources.
- Structured Input for Collections: This hierarchy is often a direct input for defining which projects a Project Collection will oversee.
How to set it up:
When creating a new project (the “Child Project”), you select an existing project from the “Parent” field. A child project can also serve as a parent to another project, allowing for multi-level hierarchies, which you can use strategically with Project Collections.
Leveraging Tags: Enhancing Collection Specificity
What are they?
Tags are keywords or labels assignable to projects. They are free-form text, offering flexibility in categorization. A single project can have multiple tags.
Why are they relevant to Collections?
- Flexible Grouping: Group projects by application, team, environment (e.g., “production,” “staging”), etc.
- Driving Collection Logic: Tags are a key mechanism for refining Project Collections. Instead of collecting all children, a collection can be configured to only aggregate data from children possessing specific tags.
- Targeted Reporting via Collections: When a Project Collection uses tags for filtering, the resulting aggregated report becomes highly specific to that tagged category.
How to use them:
Assign tags during project creation or by editing properties. The “Tags” menu offers insights, but their real power is unlocked when used as criteria within Project Collection logic.
Aggregating Insights with Project Collections: The Core Focus
What are they?
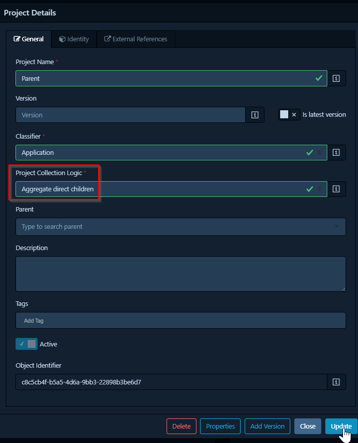
A Project Collection is a special type of project in Dependency-Track, typically designated with the classifier “Collection.” Its primary and most powerful function is to aggregate, consolidate, and display data from a defined set of other projects, often its child projects.
Important notes:
- A Project Collection itself does not have its own components, vulnerabilities, or direct policy violations. It is a special project for insights.
- All metrics and findings (like Inherited Risk Score, vulnerability counts, policy violations) displayed for a Project Collection are derived from the child projects it collects.
Why are Project Collections so crucial?
- Centralized Risk Dashboard: They provide a single, unified dashboard to oversee multiple related projects (e.g., all microservices of an application, all applications for a business unit). This is invaluable for getting a high-level understanding of risk without manually checking each project.
- Automatic Roll-up Metrics: Key metrics are automatically rolled up. This includes the critical Inherited Risk Score, total and severity-based vulnerability counts, and policy violation counts from all collected child projects.
- Simplified Portfolio Risk Reporting: Obtaining an overall risk posture for a group of projects becomes straightforward. Instead of compiling data manually, the Project Collection presents it directly.
- Effective Monitoring at Scale: As the number of projects grows, Project Collections help in monitoring them more effectively by grouping them into logical, manageable units. This is essential for teams responsible for large software portfolios.
- Targeted Analysis: Through specific collection logic (detailed below), you can create collections that focus on particular aspects, such as “all production services” or “all products from specific business unit”.
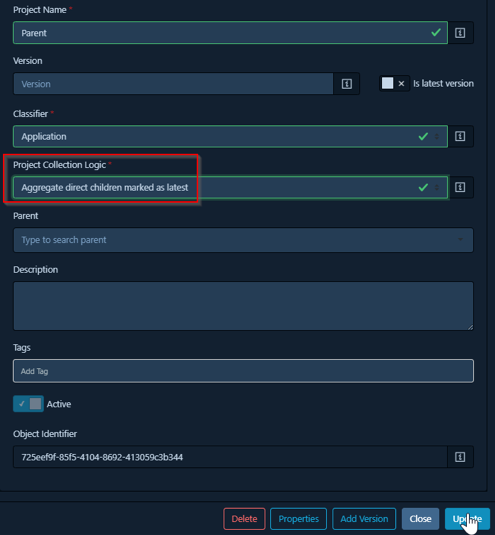
Project Collection Logic Options: Tailoring Your Aggregation
When setting up a Project Collection, you have various logic options to precisely define its data aggregation.
1. None: In this mode, the collection project does not aggregate data from any children. While less common for the primary purpose of a “collection,” it means its metrics would be its own.
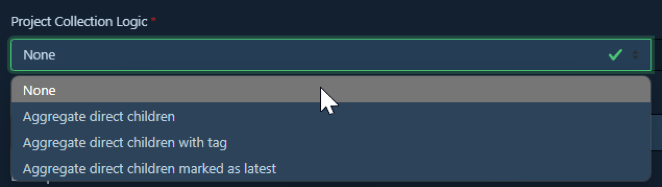
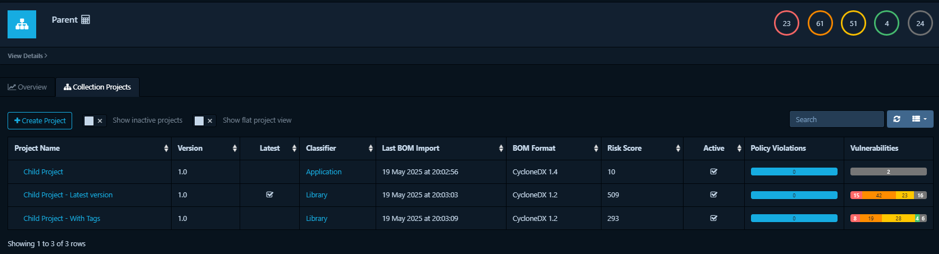
2. Aggregate direct children: The Project Collection aggregates data from all projects explicitly defined as its direct children in the parent-child hierarchy. This gives a complete overview of all components within that parent’s immediate scope.

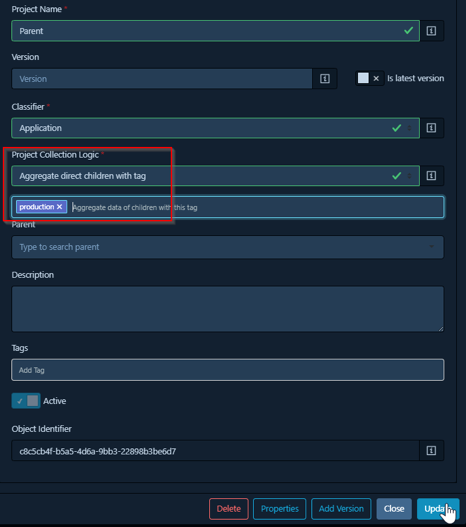
3. Aggregate direct children with tag: This option provides more refined control. The collection aggregates data only from its direct children that also possess a specific, matching tag (or set of tags). This is extremely useful for creating focused views – for example, a parent project could have a collection that only aggregates data from its child projects tagged as “production” or “customer-facing”
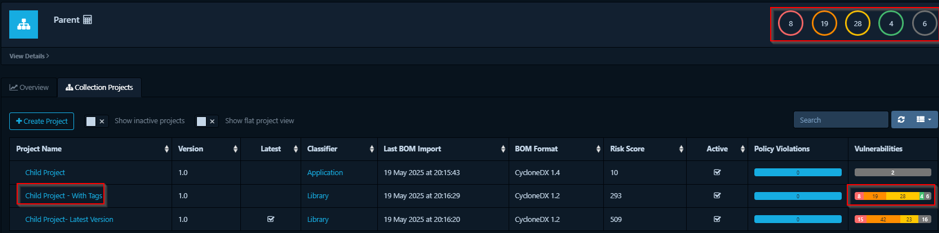
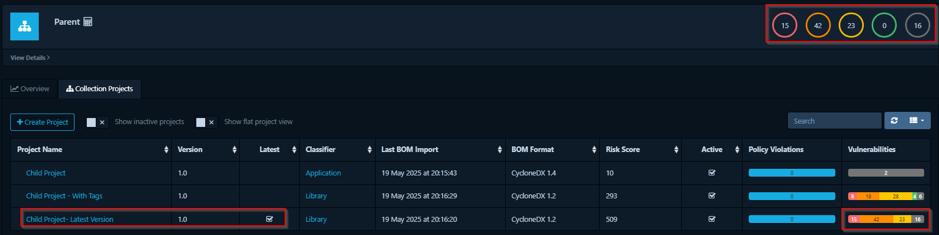
4. Aggregate direct children marked as latest: This option collects data from the versions of its direct children that are specifically marked as the “latest” version. This is crucial for focusing on the current risk posture of the most up-to-date components, filtering out noise from older, inactive versions.
Example Scenario: Project Collections in Action
Imagine a “ParentApp” project configured as a Project Collection. It has three child projects:
- MicroserviceAlpha (Version 1.0)
- MicroserviceBeta – latest (Version 2.0, marked as “latest”, tagged “production”)
- SharedLibraryGamma (Version 1.0, tagged “production”, tagged “shared”)
Let’s see how different collection logics for “ParentApp” would work:
- If “ParentApp” uses “Aggregate direct children” logic: It will include data from MicroserviceAlpha, MicroserviceBeta, and SharedLibraryGamma.
- If “ParentApp” uses “Aggregate direct children with tag” and specifies the tag “production”: It will only include data from MicroserviceBeta and SharedLibraryGamma.
- If “ParentApp” uses “Aggregate direct children marked as latest”: It will only include data from MicroserviceBeta.
This example illustrates how you can tailor Project Collections to precisely get the aggregated view you need.
Conclusion
Effectively managing your software projects in Dependency-Track is crucial for maintaining a strong security posture. While Parent-Child Hierarchies and Tags provide essential organizational structure and labelling, it is the Project Collections feature that truly unlocks a comprehensive, aggregated, and actionable view of your application landscape’s risk. By using Project Collections and their logical options, you can create insightful dashboards, track vulnerabilities with portfolio-level precision, and ultimately, make better-informed decisions to secure your software at scale.